- A+
搜了一下网上还是有不少关于关关规则的编写教程,但是大多都说的很简单对于新手朋友没有多大的参考价值,所以小编专门整理一篇“详细”的教程告诉大家到底该怎样编写关关规则,相信大家看完这篇文章后也可以独立编写关关规则了甚至售卖关关规则也不在话下。
杰奇小说站长交流qq群:144603127
打个广告 :自用关关采集器软件10元一份 关关采集规则5元一个 定制联系博主 QQ280054016
首先我们使用的是关关采集器V10.5.5757.42456版本,此版本是我们用的最顺手的一款关关,所以这篇文章也使用这款关关作为范本。
首先在教怎么编写规则前我们要先说下几个常用的正则:
\d* (\d*) 表示数字 带括号表示这个值是需要的 不带的自然是要过滤掉的
.+? (.+?) 表示内容 带括号表示这个值是需要的 不带的自然是要过滤掉的
\s* 表示空格或换行
((.|\n)*) 表示章节内容
{NovelKey} 表示小说编号
{NovelKey/1000} 表示小说编号除以1000 因为我们经常看到/44/44710/之类的
{ChapterKey} 表示章节ID
{NovelPubKey} 表示目录页地址
我们再讲一个关关通用的东西,随便加载一个规则,可以在RuleVersion中添加广告
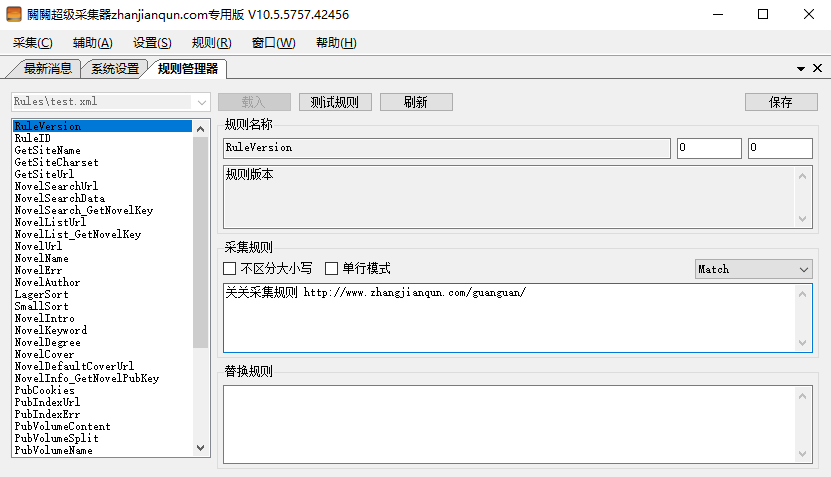
GetSiteName按照网站名填写,是笔趣阁就填笔趣阁,是顶点小说就填顶点小说,主要就是个标识。
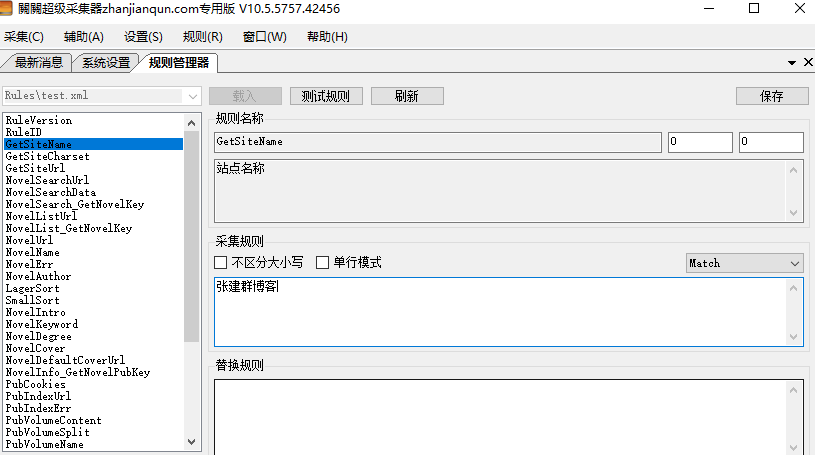
GetSiteCharset这个要认真填写,不知道就打开需要编写的网站右键查看源代码,是gbk就填写gbk,是utf8就填写utf8,gb2312就填gb2312,不要乱填,不然是乱码。
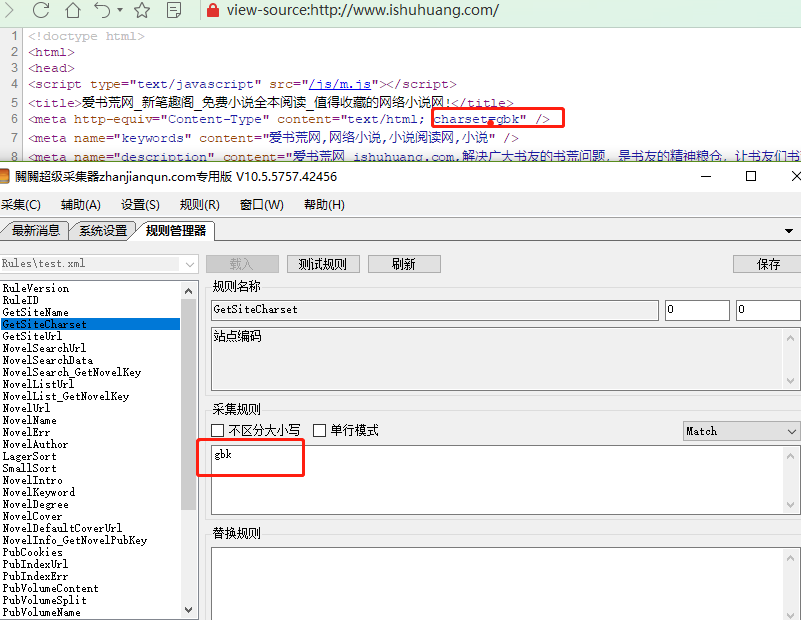
GetSiteUrl你编写的是哪个站就填写哪个站
好了,我们正式开始讲采集的事情,小编会拿出几个常见的例子来讲,首先不管什么网站我们第一个找的就是最新更新列表,后面会给大家讲几个找最新更新列表的方法。第一我们来讲笔趣阁模板,这是最常见也是需求量最大的。
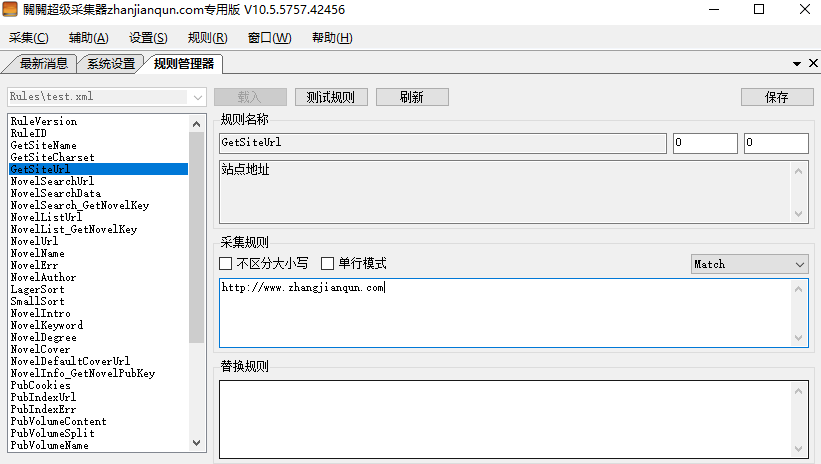
例子1:笔趣阁http://www.xbiquge.la/我们发现最新列表在首页,所以我们在NovelListUrl中就应该填写http://www.xbiquge.la/,如图
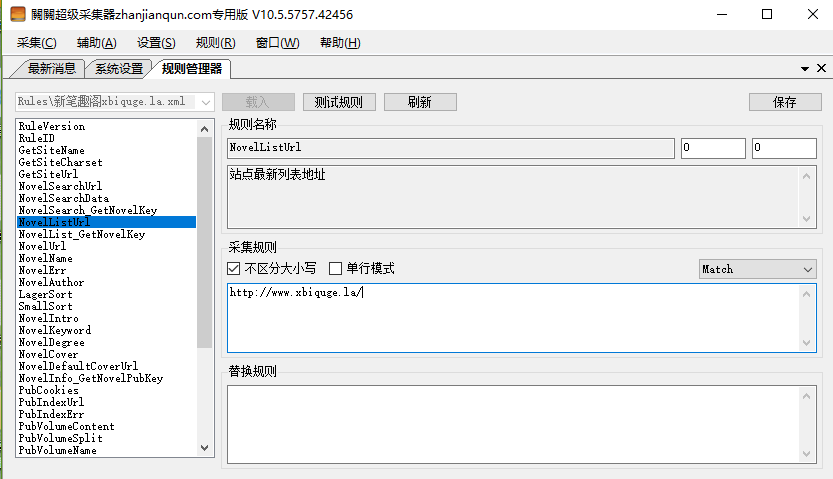
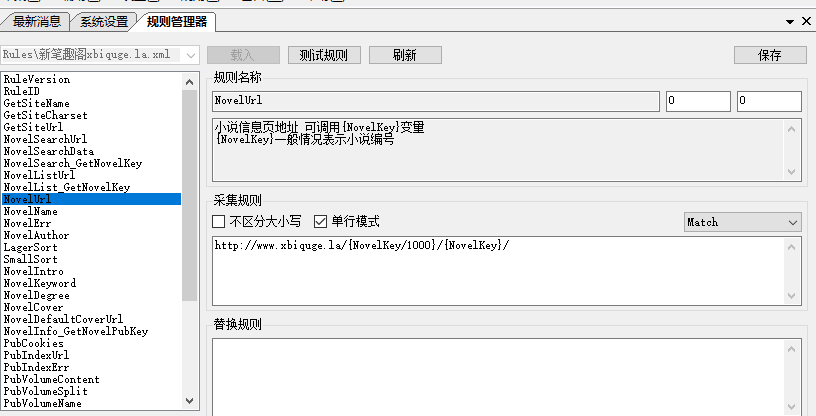
NovelList_GetNovelKey很重要,就是获取小说ID和小说名,打开笔趣阁首页右键查看源代码,找到最新更新列表,看到有小说ID和小说名的这一段内容,我们需要的就是这段内容,记住获取的这段代码必须包含小说ID和小说名并且要是唯一的,关关编写规则要点就是选择的代码必须是统一且必须是唯一的,如果不是唯一的就会获取到多个值。

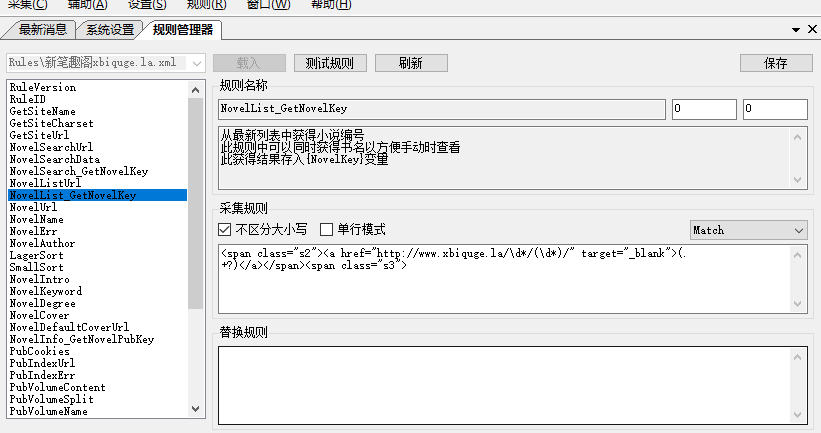
那我们关关中该如何处理这段代码,看图,其中46863这个就是小说的唯一ID,所以我们需要,所以使用(\d*),而19我们则不需要所以就使用\d*,小说名洪荒之非典型修仙是我们需要的所以我们要使用(.+?),就变成了<span class="s2"><a href="http://www.xbiquge.la/\d*/(\d*)/" target="_blank">(.+?)</a></span><span class="s3">
<span class="s2"><a href="另外一种写法/\d*_(\d*)/" >(.+?)</a></span><span class="s3">
如图所示:
这里要说明一下为什么要截取<span class="s2"><a href="http://www.xbiquge.la/\d*/(\d*)/" target="_blank">(.+?)</a></span><span class="s3">而不直接使用<span class="s2"><a href="http://www.xbiquge.la/\d*/(\d*)/" target="_blank">(.+?)</a></span>。
原因是在下面有一个最新入库小说中你会发现有一段相同的代码,而我们说过了必须要确保唯一性,所以小编才会加上<span class=”s3″>这一段来确保不会获取到错误的值。
NovelUrl小说信息页,一般笔趣阁的信息页和目录页在一个页面,所以直接填就行了。比如我们随便用一个http://www.xbiquge.la/14/14055/,这种就应该改成http://www.xbiquge.la/{NovelKey/1000}/{NovelKey}/,其中{NovelKey}在上面说了代表的意思。
/{NovelKey/1000}_{NovelKey}/
这些都搞定了我们就要开始获取小说的名字 作者 状态 封面这些了。这里要特别说明一下有个简单的方法获取到这些值,这就得感谢360结构化了,把一切就简单化了。
图片中就是所谓的360结构化,你写规则的时候首先就要去找这个东西,一般在信息页或者目录页,甚至在手机版中,如果有那么就简单多了,如果没有那就麻烦一些。
<meta property="og:title" content="洪荒之非典型修仙"/>
<meta property="og:description" content=" 穿越到封神世界,机缘巧合之下拜师申公豹,面临接下来商周大战,师傅站在了大商这边。 嗯……没说的,保住大商,跟西周死磕到底!"/>
<meta property="og:image" content="http://www.xbiquge.la/files/article/image/46/46863/46863s.jpg"/>
<meta property="og:novel:category" content="修真小说"/>
<meta property="og:novel:author" content="多来A萌"/>
<meta property="og:novel:book_name" content="洪荒之非典型修仙"/>
<meta property="og:novel:read_url" content="http://www.xbiquge.la/46/46863/"/>
我下面直接给例子,就不解释为什么了,因为大家一看就能明白,不明白的自行对找上面的截图
NovelName:og:title” content=”(.*?)”
NovelAuthor:novel:author” content=”(.*?)”
LagerSort:novel:category” content=”(.*?)”
SmallSort:novel:category” content=”(.*?)”
NovelIntro:og:description” content=”(.*?)”/>,如果(.*?)获取不了就改成((.|\n)*?)
NovelKeyword:og:title” content=”(.*?)”
NovelDegree:og:novel:status” content=”(.*?)”
NovelCover:og:image” content=”(.*?)”\s*<meta property=”og:novel:category” 为什么获取封面要这么写,实测过如果没有封面会获取到另一个值,甚至是对方的网址,这不是我们希望看到的。
NovelDefaultCoverUrl:一般填写nocover.jpg或者noimg.gif,大多数为nocover.jpg,基本没有第三种。
NovelInfo_GetNovelPubKey:novel:read_url” content=”(.*?)”
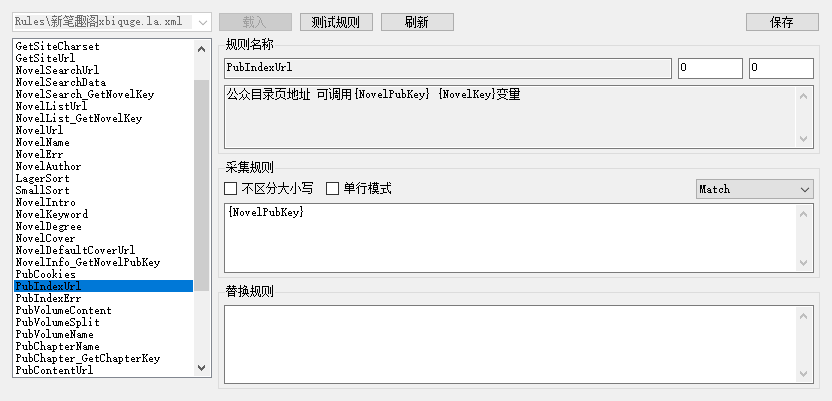
PubIndexUrl:如果信息页和目录页是一个可以直接填写{NovelPubKey},如果不一样就像写NovelUrl一样写目录页地址就行了
PubVolumeContent这个后面讲,一般来说不需要用到这个
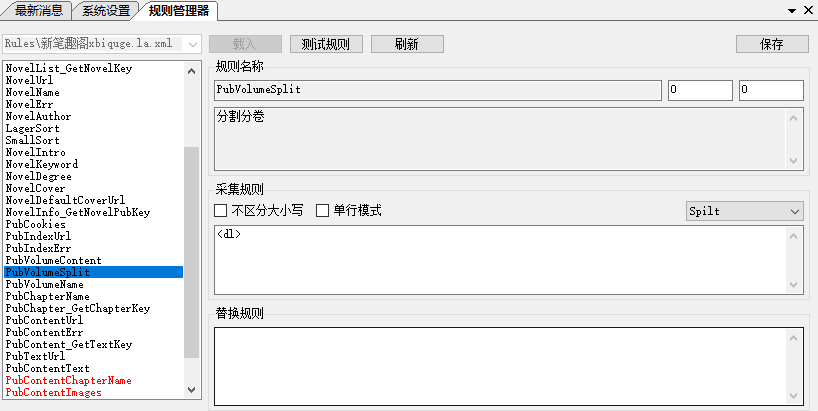
PubVolumeSplit和PubVolumeName的用处就是分割分卷和获取分卷名,其实按道理来说写不写都可以,因为没用,但是必须要写,因为不写有时候无法采集,至于怎么写打开目录页右键源代码
因为没有分卷,所以我们就用这一段就行了,获取不获取值不重要,因为我们采集的时候都要勾选禁止添加分卷。看图
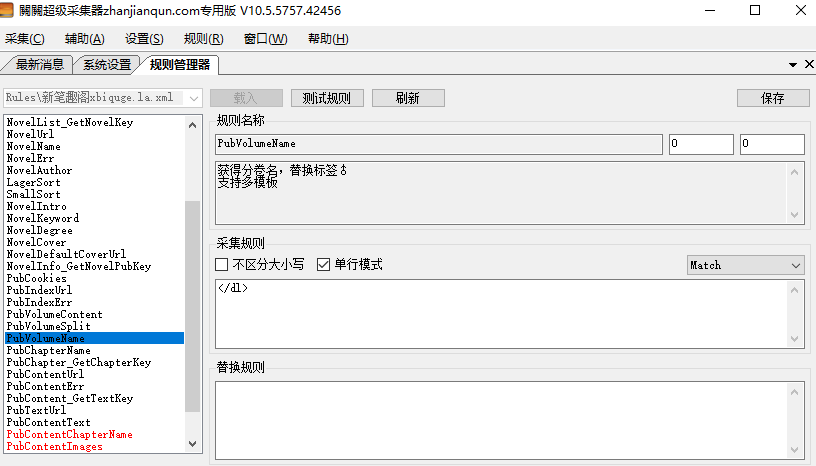
PubChapterName获取章节名和PubChapter_GetChapterKey获取章节ID是比较重要的,
选取列表中统一的值,已经用蓝色阴影标识
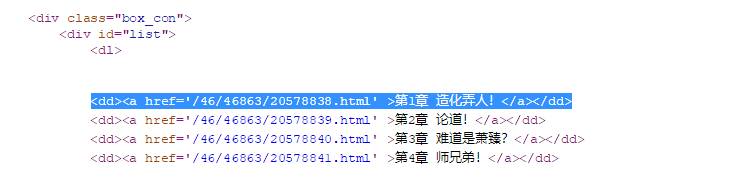
PubChapterName直接这样写就行了<dd><a href='.+?' >(.+?)</a></dd>,因为a href中的值是不需要的直接过滤就行了,这样写还有一个好处,后面讲
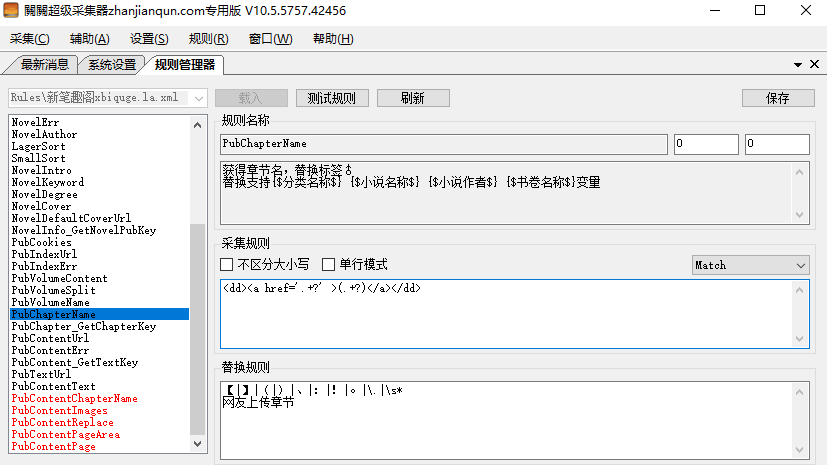
PubChapter_GetChapterKey就要这样写了:<dd><a href='/\d*/\d*/(\d*).html' >.+?</a></dd>,因为20578838这个是我们需要的章节ID,所以要用(\d*)
<dd><a href='/\d*/\d*/(\d*).html' >.+?</a></dd>
<dd><a href="/\d*_\d*/(\d*).html">.+?</a></dd>
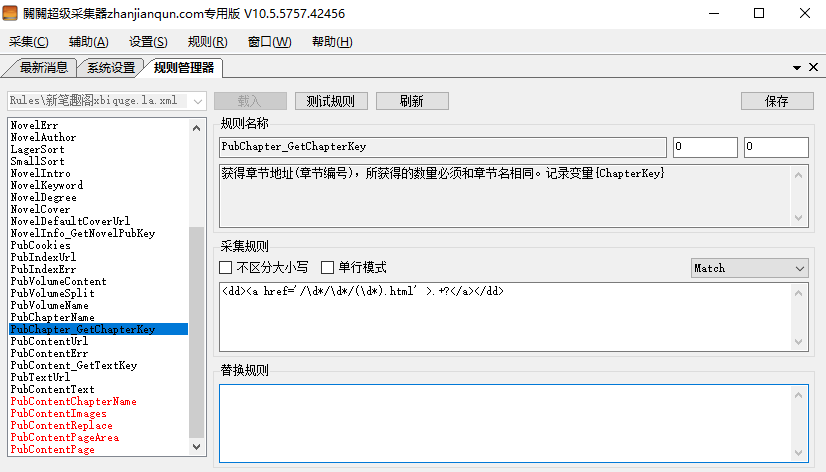
我们最后要写的就是PubContentText这个了,也就是获取章节内容,同样打开章节页面右键源代码,找到章节内容
选取<div id=”content“>内容</div>结尾,写成<div id=”content”>((.|\n)+?)</div>就行了,基本上笔趣阁都这样。
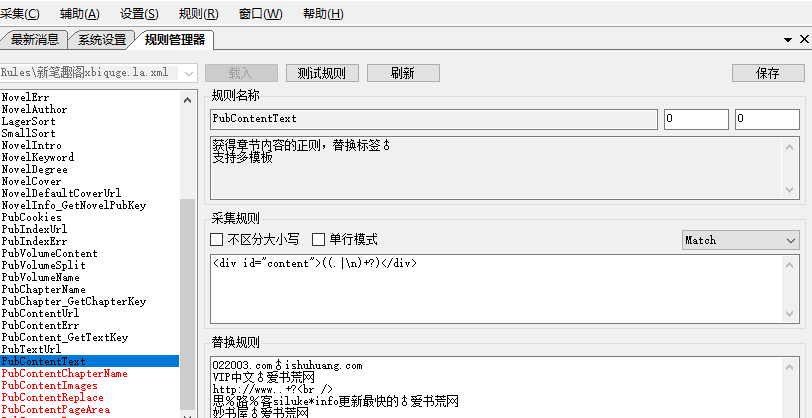

然后就是去广告了,在替换规则中填入你想要去掉的广告,一行一个或者用|分割掉,如果你想替换就这样写 笔趣阁♂爱书荒网,替换标识符为♂,这样笔趣阁这三个字就变成爱书荒网了
022003.com♂ishuhuang.com
VIP中文♂爱书荒网
http://www..+?<br />
思%路%客siluke*info更新最快的♂爱书荒网
妙书屋♂爱书荒网
<p>.*?</p>
去广告不需要什么技术,只要多找就行了,如果你遇到这种一段话的,比如:恋上你看书网 WWW.630BOOK.LA ,最快更新大红娘最新章节!直接写成 恋上你看书网.+?最新章节!就行了,没必要分割一个个去掉。
最后测试规则就行了,一个基本的规则就这样写,很简单多玩一下就懂了,下面我讲一些遇到的问题以及你在网上查不到的资料。
如果没有360结构化的我们该怎么写,其实也很简单就是找相关信息而已,就是麻烦一些。
用一个少年文学网的例子来说:https://www.snwx8.com
打开信息页,右键源代码,找到相关信息,如下图
<div id="info">
<div class="infotitle">
<h1>校园绝品狂徒</h1>
<i>作者:柳江南</i>
<i>类别:都市小说</i>
<i>状态:连载中</i>
</div>
<div class="intro">
<b>小说校园绝品狂徒简介:</b><br /> 在学校受够欺辱的西门宇,在一次偶然机遇下获得异能修炼,在那几个奇怪的老头师傅各种折磨下终究修炼成功,下山归来,热血爆,面对那些家族,他必定要报复,看看我们的男猪脚会怎样吧。
</br>各位书友要是觉得《校园绝品狂徒》还不错的话请不要忘记向您QQ群和微博里的朋友推荐哦!校园绝品狂徒最新章节,校园绝品狂徒无弹窗,校园绝品狂徒全文阅读.
</br>各位书友要是觉得《校园绝品狂徒》还不错的话请不要忘记向您QQ群和微博里的朋友推荐哦!<b>关键词:</b>校园绝品狂徒最新章节,校园绝品狂徒无弹窗,校园绝品狂徒全文阅读.
</div>
<div id="fmimg"><img alt="校园绝品狂徒" src="https://www.snwxx.com/files/article/image/0/381/381s.jpg"
直接给写法,就不解释了,因为解释的话太累了,又得写很多,自行对比就行了,反正记住唯一性就行了。
NovelName:<title>(.+?)最新章节列
NovelAuthor:作者:(.+?)</i>
LagerSort:类别(.+?)</i>
SmallSort:类别(.+?)</i>
NovelIntro:简介:((.|\n)*?)</br>各位书友要是觉
NovelDegree:状态:(.+?)</i>
NovelCover:<div id=”fmimg”><img alt=.+?src=”(.+?)”
基本就这样,请自行对比代码,至于NovelIntro小编为什么要这样写,你写一遍就明白了。
解决新笔趣阁等获取不到最新章节的的问题,我们先看下图会发现最新章节多了一段代码,所以获取不了。
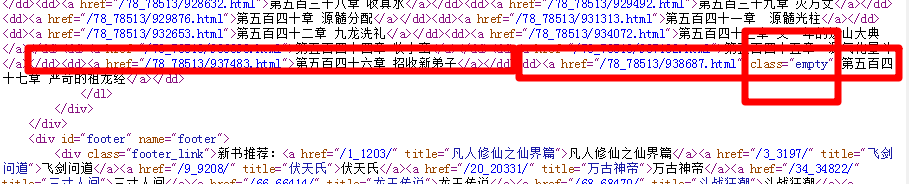 解决方法在PubChapterName直接这样写就行了<dd><a href=”.+?”>(.+?)</a></dd>上面说的好处就是这个,或者写成<dd><a href=”/\d*_\d*/\d*.html.+?>(.+?)</a></dd>也可以
解决方法在PubChapterName直接这样写就行了<dd><a href=”.+?”>(.+?)</a></dd>上面说的好处就是这个,或者写成<dd><a href=”/\d*_\d*/\d*.html.+?>(.+?)</a></dd>也可以
这样就能解决这种获取不到最新章节的情况。
目录拼音化的写法,打开小说骑士www.xs74.com我们发现目录是拼音化的解决方法很简单写法都是一样的,只是把(\d*)换成(.+?)就行了,如下:<span class=”s2″><a href=”https://www.xs74.com/novel/(.+?)/” target=”_blank”>(.+?)</a></span>
这个解决了然后我们发现这个阅读页居然是分页的,正常写出来只能获取到第一页的.
这个我们看一看手机站会发现内容是完整的没有分页,所以我们直接把PubContentUrl改成手机页的就行了:https://m.xs74.com/novel/{NovelKey}/{ChapterKey}.html.
再次测试就能获取到全部内容了,如果手机版也是分页的我们一般就需要写PHP文件外挂采集了,这个教程不说php相关教程,不然没完没了的,而且不懂代码的理解比较难,你只要看完本教程基本可以通杀98%小说站了。
我这边再说一个东西,这边我现在找不到这个例子了,因为网站没了或者改版了。情况就是章节列表是不规则的,每4节重复,这种也是可以解决的,就是把不规则的地方给规则话就行了,这时候需要使用[“‘]来规则化。
PubChapterName:<dd><a.+?ref=[“‘]/yikan/\d+/\d+.html.+?>(.+?)</a>
PubChapter_GetChapterKey:<dd><a.+?ref=[“‘]/yikan/\d+/(\d+.html).+?>.+?</a>
如果你们遇到这样的自行对比吧,稍微复杂一些。
还有上面曾经说过的PubVolumeContent,这个拿棉花糖小说网来举例http://www.mianhuatang.la
我们在写到列表的时候测试会发现第一章获取到的居然不是第一章而且最新九章,九章过后才是第一章,这样采集不是很蛋疼。
这种情况就需要定义PubVolumeContent了,写成</h2><dl>((.|\n)+?)</dl>就行了,至于为什么就自行对比吧。
暂时就写到这里吧,想到什么再补充,也希望大家多多支持张建群博客,有问题可以留言。
- 我的微信
- 这是我的微信扫一扫
-

- 我的微信公众号
- 我的微信公众号扫一扫
-